SICSS-Oxford Prediction Competition!
Time: 14:00-15:45 on the 5th July, 2022
Location: Classroom 1, Said Business School
Prizes: Top Secret!
Welcome to the top secret SICSS-Oxford Prediction Competition (with prizes)! Having learnt all about how machine learning and prediction more generally works this morning, we're now going to put it all into practice with some group exercises. At this point in time, we're going to randomly allocate you into six groups of four.
Great, now that we're in our groups of four, lets outline the task. Here is your first dataset -- train.csv -- which contains various bits of information. The prediction competition is in itself fairly simple: build an algorithm which can predict income out-of-sample. The train.csv file has 70k rows of data, with income within it. Here is test_x.csv which you should use to generate your predictions for a hidden 30k rows of income at the individual micro-level for people across the United Kingdom. Note: text_x.csv does not have the hidden income data within it! This is what you should be predicting!
But what is in this dataset?
sector: A range of twelve different industry classifications familiar to the UK.seniority: Three levels of seniority: entry level, middle, senior.based_in_london: A binary variable as to whether the individual works in London.sex_mf: A sex variable which denotes male or female.private_school: A binary variable which denotes whether an individual went to a private school.oxbridge: A binary variable which denotes whether an individual went to Oxford or Cambridge.education: An ordered categorical variable which denotes whether somebody had some high school, an undergraduate degree, or a masters degree.age: Fairly self explanatory (continuous), bounded between 18-65.height: Fairly self explanatory (continuous), bounded between 140-190.union: Whether the worker is part of a labour union.favourite: The person's favourite colour.
To make this even more fun, there is random missingness in some, but not all variables. The evaluation metric that we will use in this prediction competition is everybody's favorite pseudo-R2:
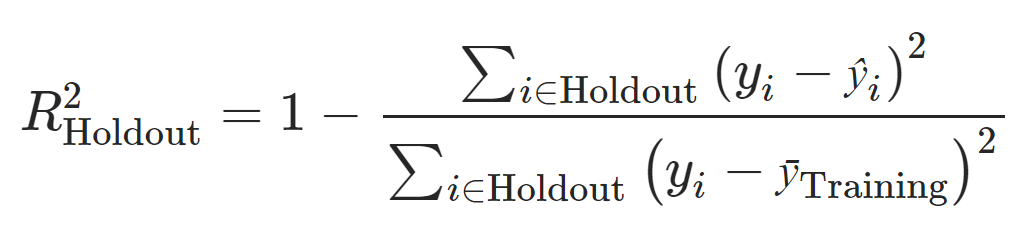
You should submit your group's predictions (how about you come up with a fun fancy team name to differentiate yourselves?) to sicss.oxford@nuffield.ox.ac.uk by 15:30. Note: This should just be a single column of predictions with no index where possible. Shortly afterwards we'll evaluate the predictions and then subsequently announce a winner!